
Troughs usually precede inspiring slopes and productive plateaus

Words matter. But so does context.
Terms like ‘trough of disillusionment” from Gartner’s (in)famous Hype Cycle appear to have obvious negative implications.
Being in any kind of trough can’t be a good thing right? (farmyard animals and drunken cowboys from 1950s films and TV aside)
But a little bit of analysis, or simply engaging with the detail, reveals a more nuanced story. And let’s face it, amid all of the current hype around Gen AI, a little bit of nuance should be welcome.
As Gartner’s prognosticator in chief, or to give him his correct title Distinguished VP analyst, chief of research, John Lovelock explained it this week:
“For AI we are in the trough of disillusionment this year,” he said speaking on a webcast to explain Gartner’s latest quarterly IT spending predictions. “The lowest point for expectations. But let’s be careful to remember that expectation is the vertical axis of the hype cycle. It is not what the technology can do, it is what the users of the technology expect it to do and right now it is at a low point.”
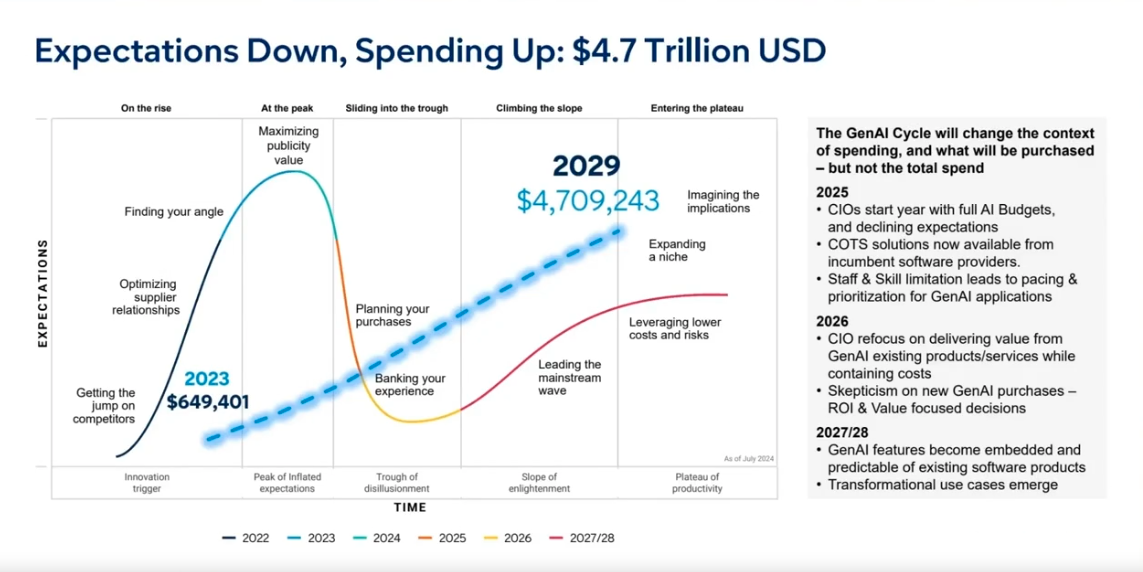
So what Lovelock is explaining is that not that Gen AI is inherently bad or not delivering but rather that customers have adjusted their expectations based on their experience of AI to date. As Lovelock explains: “Even though we are in the trough of disillusionment we are seeing overall AI spending continue to grow. It will hit $4.7 trillion by 2029.”
“It is not what the technology can do, it is what the users of the technology expect it to do and right now it is at a low point.”
Gartner’s John Lovelock explaining how to interpret the Hype Cycle
$4.7 trillion by 2029! That is not a small number. (for context, Gartner predicts that worldwide IT spending is expected to reach $6.31 trillion in 2026, up 13.5% from 2025).
AI being in the trough, needs to be understood in the broader context of the Hype Cycle. Following the trough, there is fortunately a slope, then a plateau. Everyone loves a plateau – especially a plateau of productivity.
But while Gartner was positive about the future promise of AI, there are some well documented challenges ahead when it comes to the small matter of return on investment (ROI). Lovelock went on to discuss the thorny issue of how hyperscalers will recoup the hundreds of billions invested into new data center capex over the recent past which is expected to continue into the near future at least.
Not even including the data center physical infrastructure (power, cooling, building shell etc), there is a significant gap between projected future revenues from selling AI services versus the investment in AI IT infrastructure.
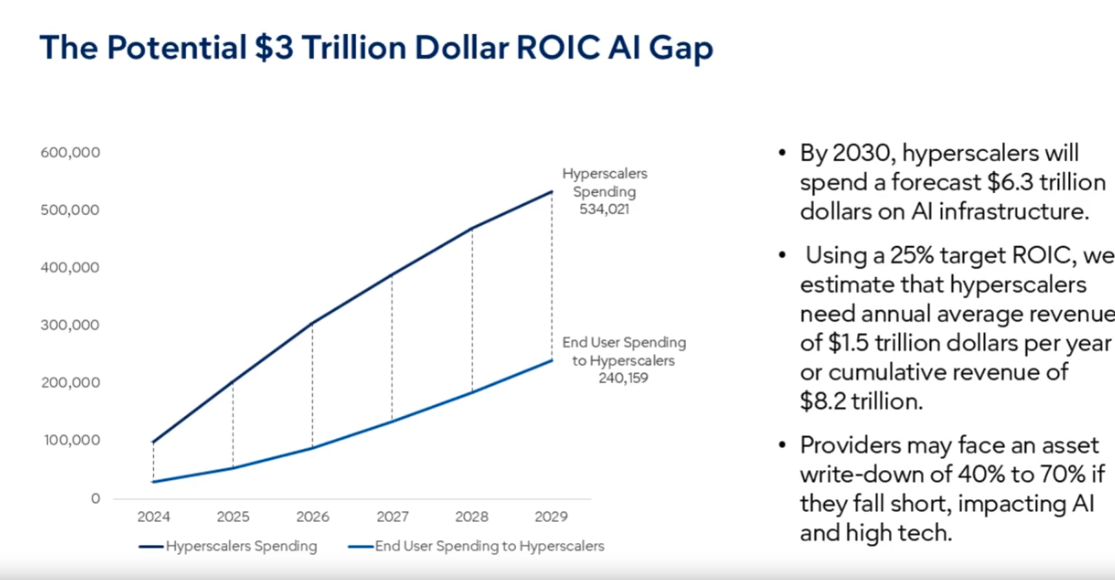
“We notice there is a tremendously large gap,” said Lovelock. “If these hyperscalers are to meet the return on investment of 25% for just the servers and networking equipment they are going to need about $1.5 trillion dollars in revenue.”
“If they stuck to their current revenue models they would be in trouble,”
John Lovelock, Gartner
However, again, the nuance matters. Lovelock explained that if the hyperscalers were approaching AI in the same way as say cloud, they could be facing a write down on some of the capital investment by 2029, 2030. “If they stuck to their current revenue models they would be in trouble,” he said.
But most hyperscalers appear to be diversifying their revenue streams, using AI servers to buy interests in new AI start-ups for example. The take-away message from Lovelock is that the dynamic and fluid nature of AI investments, adoption and monetization make simplification a dangerous game. “The market is tremendously complicated. Looking at it through a simplified lens could lead you to a simple outcome that is not likely to happen”.
So there you have it. Words matter. And being in a trough is not necessarily bad if there is a beautiful plateau in your future too.
The full webcast is available here. There is also some good analysis of the impact of AI on jobs which is also worth chewing over.



 My new role at Vertiv has kept me busy – in an exciting way – over the last couple of months so I’ve been a bit remiss in keeping this blog up to date.
My new role at Vertiv has kept me busy – in an exciting way – over the last couple of months so I’ve been a bit remiss in keeping this blog up to date.




You must be logged in to post a comment.